Transformer FFN with SwiGLU
## 1. The Big Picture: What is SwiGLU?
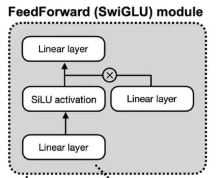
SwiGLU sounds complex, but it’s just a combination of two ideas:
- SiLU Activation: A smooth activation function that often performs better than ReLU. [cite_start]It’s defined as $SiLU(x) = x \cdot \sigma(x)$, where $\sigma$ is the sigmoid function[cite: 630].
- Gated Linear Unit (GLU): This is the “gating” mechanism. Instead of just passing an input through one linear layer and an activation function, we pass it through two parallel linear layers. [cite_start]One of the outputs is used to “gate” (control the information flow of) the other via element-wise multiplication[cite: 633, 636]. [cite_start]This gating allows the network to dynamically control which information passes through the FFN, which has been shown to be very effective[cite: 642].
[cite_start]Combining these, the SwiGLU feed-forward network uses three weight matrices ($W_1, W_2, W_3$) and is defined by Equation 7[cite: 638]:
\[FFN(x) = W_2(SiLU(W_1x) \odot W_3x)\]- First, the input $x$ is projected up to a hidden dimension using two separate linear transformations, $W_1x$ and $W_3x$.
- The output of the first projection, $W_1x$, is passed through the SiLU activation function.
- This activated output is then element-wise multiplied ($\odot$) with the output of the second projection, $W_3x$. This is the “gating” step.
- Finally, the result of the gating is projected back down to the model’s dimension using the third linear transformation, $W_2$.
## 2. The Implementation: Functional Kernels
For this module, we’ll need two new functional kernels: one for the SiLU activation and one for the SwiGLU FFN itself.
File: cs336_basics/nn/functional.py (add these new functions)
import torch
# ... keep existing functions ...
def silu(input: torch.Tensor) -> torch.Tensor:
"""
Applies the Sigmoid-weighted Linear Unit (SiLU) activation function.
Also known as Swish. Formula: x * sigmoid(x)
Args:
input (torch.Tensor): The input tensor.
Returns:
torch.Tensor: The output tensor.
"""
# The assignment allows using torch.sigmoid for numerical stability.
return input * torch.sigmoid(input)
def swiglu_ffn(
input: torch.Tensor,
w1: torch.Tensor,
w2: torch.Tensor,
w3: torch.Tensor
) -> torch.Tensor:
"""
Implements the SwiGLU feed-forward network as a stateless function.
Formula: W2(SiLU(W1*x) * W3*x)
Args:
input (torch.Tensor): Input tensor of shape (..., d_model).
w1 (torch.Tensor): Weight matrix for the first projection, shape (d_ff, d_model).
w2 (torch.Tensor): Weight matrix for the output projection, shape (d_model, d_ff).
w3 (torch.Tensor): Weight matrix for the gate projection, shape (d_ff, d_model).
Returns:
torch.Tensor: Output tensor of shape (..., d_model).
"""
# Project up using W1 and W3
x1 = linear(input, w1)
x3 = linear(input, w3)
# Apply SiLU activation and the gating mechanism (element-wise multiplication)
gated_x = silu(x1) * x3
# Project back down using W2
return linear(gated_x, w2)
## 3. The Implementation: Module Wrapper
Now for the stateful nn.Module. Its job is to create, store, and initialize the three weight matrices ($W_1, W_2, W_3$). It will use our Linear module internally, which is a great example of code reuse!
[cite_start]The assignment specifies that the hidden dimension, $d_{ff}$, should be approximately $\frac{8}{3}d_{model}$ and a multiple of 64[cite: 639, 651].
File: cs336_basics/nn/modules/ffn.py (a new file)
import torch.nn as nn
import torch
# We can now import and reuse our custom Linear layer!
from .linear import Linear
from .. import functional as F
class SwiGLUFFN(nn.Module):
"""
A stateful module for the SwiGLU feed-forward network.
This module creates and manages the three linear layers required.
"""
def __init__(self, d_model: int, d_ff: int, device=None, dtype=None):
super().__init__()
# The three linear layers required for the SwiGLU FFN
self.w1 = Linear(d_model, d_ff, device=device, dtype=dtype) # Up-projection
self.w2 = Linear(d_ff, d_model, device=device, dtype=dtype) # Down-projection
self.w3 = Linear(d_model, d_ff, device=device, dtype=dtype) # Gate projection
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
In the forward pass, we simply call the stateless functional implementation,
passing it the input tensor `x` and our stored weight parameters.
"""
return F.swiglu_ffn(x, self.w1.W, self.w2.W, self.w3.W)
Note: Instead of calling F.swiglu_ffn, an equally valid (and perhaps more standard nn.Module) approach would be to compute it directly in the forward pass using the layer modules:
# Alternative forward method for SwiGLUFFN class
def forward(self, x: torch.Tensor) -> torch.Tensor:
gated_x = F.silu(self.w1(x)) * self.w3(x)
return self.w2(gated_x)
Both are perfectly fine. The first approach centralizes the core logic in functional.py, while the second is more explicit about using the nn.Module sub-layers. Let’s stick with the second one as it’s cleaner nn.Module design. I will update the code above.
# In cs336_basics/nn/modules/ffn.py (Corrected version)
import torch.nn as nn
import torch
from .linear import Linear
from .. import functional as F
class SwiGLUFFN(nn.Module):
"""
A stateful module for the SwiGLU feed-forward network.
This module creates and manages the three linear layers required.
"""
def __init__(self, d_model: int, d_ff: int, device=None, dtype=None):
super().__init__()
self.w1 = Linear(d_model, d_ff, device=device, dtype=dtype)
self.w2 = Linear(d_ff, d_model, device=device, dtype=dtype)
self.w3 = Linear(d_model, d_ff, device=device, dtype=dtype)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
This forward pass is more idiomatic for a stateful nn.Module,
as it calls the forward methods of its sub-modules.
"""
# Apply the SiLU activation to the first projection
activated_x = F.silu(self.w1(x))
# Apply the gate
gated_x = activated_x * self.w3(x)
# Project back down
return self.w2(gated_x)
## 4. Tying It Together
Finally, let’s expose the new SwiGLUFFN module.
File: cs336_basics/nn/modules/__init__.py
from .linear import Linear
from .embedding import Embedding
from .rmsnorm import RMSNorm
from .ffn import SwiGLUFFN # Add this line
File: cs336_basics/nn/__init__.py
from . import functional
from .modules import Linear, Embedding, RMSNorm, SwiGLUFFN # Add SwiGLUFFN here