Paper - ATTENTION SINKS
Paper: EFFICIENT STREAMING LANGUAGE MODELS WITH ATTENTION SINKS
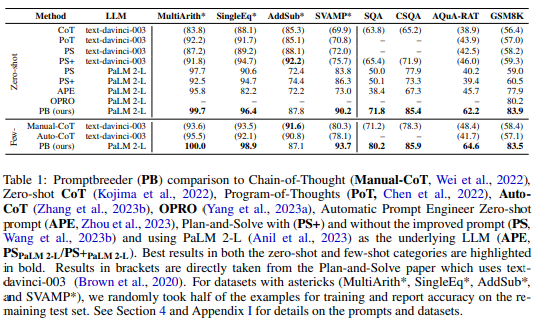
Notes
- Problem?
- Need of LLM which will have unlimited context length.
- Current limitation
- attention matrix is compute heavy
- immediate solution is we can use a sliding window which can cater to only recent tokens, new tokens and related calculation added and old will be removed from the cache. This method fails as soon as we cross the original attention window of training.
- While investigating this they found that major cause of this breakage is to not have the 0,1,2 … few initial tokens, it is being hypothesised that the attention mechanism is dumping a lot of unused attention values to initial few tokens, as we use the sliding window mechanism the initial tokens are not present and attention mechanism fails to dump the unused attention to initial positions.
- Solution is instead of dropping the initial few tokens we will drop the middle ones. This way with new token we will keep the old cache attention as it is. We will calculate the attention for new token. and to compensate the window limit we will drop the middle tokens.
- Idea here is, suppose we want to predict the 9th token [0,1,2,3,6,7,8] the position 4,5 are dropped to acccomodate the new token. Now when we want to predict the 9th token, we reformat the question to language model saying we have,[0,1,2,3,4,5,6] and we are predicting 7th token (we are shifting the 6,7,8 by number of dropped tokens) this to compensate for how the training has happened, while training we indeed have these token available. again we obviously have lost some intermediate info if it works then we did not need info OR could be statistical fluke
Thoughts
- Good direction, however while training the q, k, v values are optimised to full attention span. Its may happen that there could be important word which we will miss sue to intermediate attention, theoretically.
- if it works, it might be due to language that we might not need all attention to all words after all.
keywords learn/search
- attention window
- attention dump to initial tokens
ref